
本記事の内容
本記事は、基本情報技術者試験におけるデータ構造、アルゴリズム、プログラミングについて、情報及びコンピュータの素人目線から説明する記事です。
本記事を読むに当たり、特別必要な知識はありません。
前回の記事(集合、論理演算、論理回路、オートマトン)は以下をご覧ください!

本ブログでは集合・論理・写像や実数の連続性、群論やグラフ理論など基礎的な大学数学(主として大学1,2年向けの数学)を解説しておりますので、そちらの記事もぜひご覧ください!

本記事の概観
本記事では
コンピュータがどのようにデータを処理しているか
を述べます。
データ構造
コンピュータは複雑な処理を行っています。
しかし、コンピュータが処理の途中で迷子になることはありません。
なぜならば、データの並べ方を工夫しているからなのです。
コンピュータが扱う情報のこと「データ」といいます。
データはコンピュータ内にある「主記憶装置」と呼ばれる記憶装置に保存されます。
(※主記憶装置については後の記事で述べます。)
コンピュータの処理効率はデータの並べ方で大きく変わります。
故に、主記憶装置に保存されているデータは、処理の内容はその時の状況に応じて、様々な方式で並べられます。
この主記憶装置上のデータの並べ方のことをデータ構造といいます。
データ構造
主記憶装置上のデータの並べ方のことをデータ構造という。データ構造の種類
データ構造の種類は、以下の5種類が存在します。
すなわち、主記憶装置上のデータの並べ方が5種類存在します。
- スタック:最後に格納したデータを最初に取り出す方式
- キュー:最初に格納したデータを最初に取り出す方式
- 配列
- 連結リスト
- 木構造
基本情報技術者試験では、「データの構造の種類」と「それぞれの特徴」が問われます。
※ちなみに、試験では「スタック」が最頻出のようです。
スタック
スタック
スタックとは、データを1列に並べて、最後に格納したデータを最初に取り出すデータ構造を指す。イメージとしては、積み上げられた本です。
1冊の本がデータに対応しています。
本を積み重ねるときは順々に上に上に積み重ねます(データを保存するとき)。
一方で、取り出すときは、1冊ずつ最上部から取り出します(データを取り出すとき)。
この構造がスタックです。
途中にある本を一気に取り出すことは出来ないことに注意です。
スタックの最大の特徴は
コンピュータがいつでも元の処理に戻ることでできる点
です。
なぜならば、保存されている処理の履歴を順々に1つずつ戻っていけば、元の処理にたどり着くからです。
ヘンゼルとグレーテルという童話で、ヘンゼルがパンくずを落としながら森の中を歩き、予め落としてきたパンくずを目印にして元の場所に戻るという描写がありますが、そんな感じです。
スタックへのデータの出し入れ
push、pop
- push スタックにデータを格納することをpush(プッシュ)という。
- pop スタックからデータを取り出すことをpop(ポップ)という。
例えば、「X」というデータをスタックに格納する場合は、「push X」と書きます。
しかし、取り出す場合は「push」のみです。
なぜならば、スタックは、最上部に格納されているデータ(つまり、一番最後に格納したデータ)しか取り出せないので、pushのようにデータを指定する必要がないからです。
つまり、「pop X」のような書き方はしません。
ちなみに、スタックのように、後に入れたデータを先に取り出すアルゴリズムを後入れ先出し(LIFO:Last In First Out)といいます。

キュー
キュー
キューとは、データを一列に並べて、最初に格納したデータを最初に取り出すデータ構造を指す。また、待ち行列とも呼ばれる。ところてんのような方式です。
もっと身近で言えば、レジ待ちのお客さんといったところです。
お客さんがデータです。
お客さんは列の最後に並び、最初に並んだ人が最初に会計をします。
列の途中に割り込むことは出来ません(データとデータの間にデータを格納することはできない)。
キューというデータ構造を使うメリットは
命令を入力した順番通りに処理できること
です。
キューへのデータの出し入れ
enqueue、dequeue
キューにデータを格納することをenqueue(えんきゅー)といい、キューからデータを取り出すことをdequeue(できゅー)という。例えば、「X」というデータをキューに格納する場合は、「enqueue X」と書きます。
しかし、スタックと同様に取り出すデータは決まっていますので、「dequeue X」とは書きません。
ちなみに、キューのように先に入れたデータを先に取り出すアルゴリズムを先入れ先出し(FIFO:First In First Out)といいます。

配列
配列、要素、添字
配列とは、データを表の形に並べたデータ構造を指す。また、配列において1つ1つのデータを要素と呼び、要素の位置を表す数字を添字という。ただし、プログラムの言語によっては、添字をインデックスと呼ぶこともある。
要するに、表の中にデータを入れたり取り出したりする事ができる構造を配列と呼ぶわけです。
一次元配列
一次元配列
配列の中でも、要素が一列にならぶ配列を一次元配列という。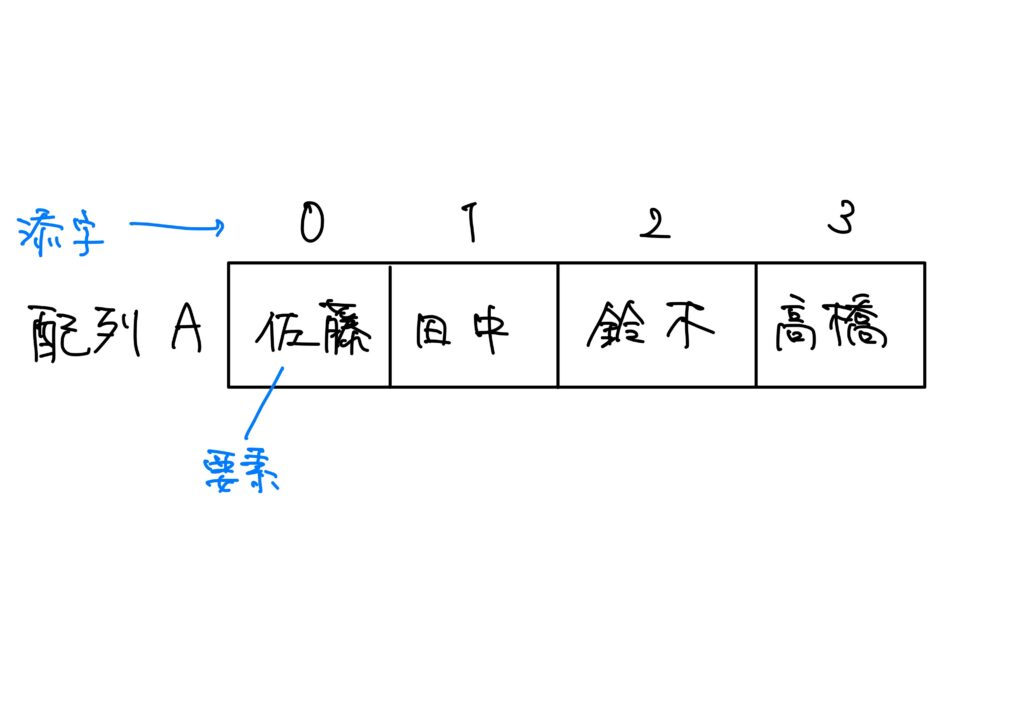
添字が「1」からでなく「0」から始まっている、と言うことに注意です。
コンピュータのデータ構造では、番号は通常0から始まります。
配列から1つの要素を取り出す
配列から1つの要素を取り出す場合は配列の後に( )をつけて、その中に添え字を書きます。
例えば、先程の図の中にある配列Aの先頭から3番目の要素である「鈴木」を取り出す場合は「A(2)」と書きます。
つまり、「A(2)=鈴木」です。

ちなみに、( )は[ ]の場合もあります。
C言語では[ ]を用います。
二次元配列
二次元配列
配列の中でも、要素が縦横に並ぶ配列を二次元配列という。
二次元配列では要素の横の並びを「行」、縦の並びを「列」といいます。
数学における行列と同じです。
二次元配列から要素を取り出す場合は、添字を「行,列」で指定します。
例えば、上図の二次元配列Aの1行3列の要素である「東京都」を取り出す場合は「A(1,3)」と書きます。
つまり、「A(1,3)=東京都」です。
連結リスト
連結リスト
連結リストとは、データを数珠つなぎに並べたデータ構造を指す。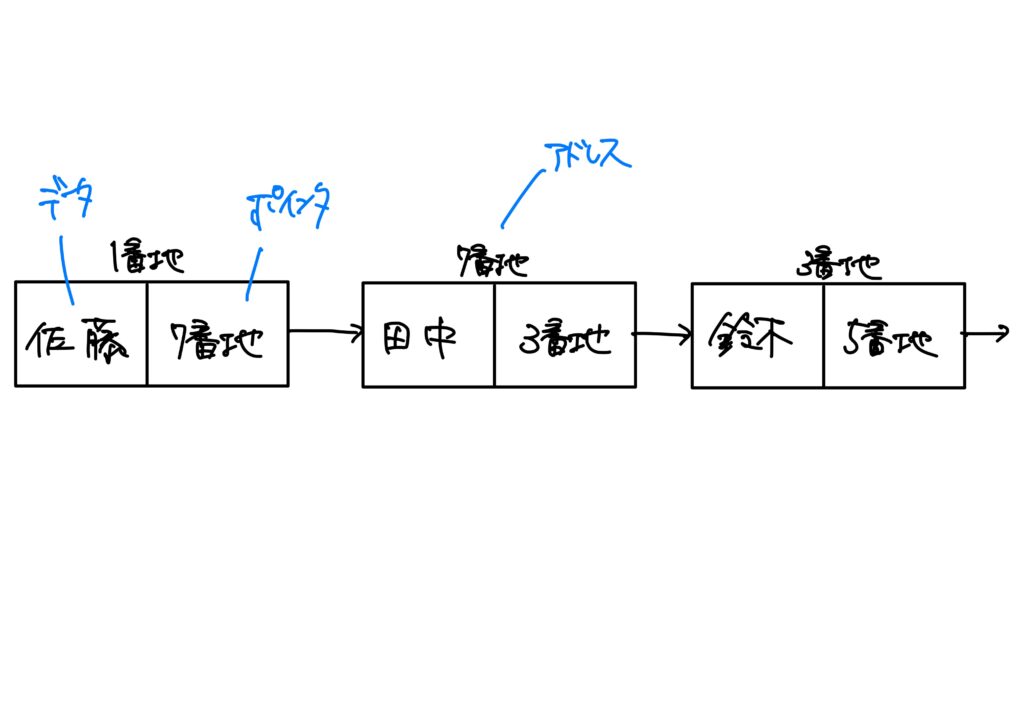
連結リストも配列と同様に、個々のデータを要素と呼びます。
ただし、連結リストの要素は配列の要素とは異なり、データにポインタが付きます。
ポインタ
ポインタとは、次の要素のアドレス(主記憶装置上のデータの位置)を指し示す情報を指す。連結リストでは、ポインタを用いて、要素を数珠つなぎにします。
コンピュータでは、ポインタに格納されているアドレスぅをたどることで、目的のデータにアクセスします。
要するに、上図のように、1番地には「佐藤」と「7番地」というデータが格納されており、次にポインタである「7番地」にアクセスして「田中」と「3番地」というデータにアクセスします。
同様にその次は3番地にアクセスして…ということを繰り返して目的のデータにアクセスするのが連結リストです。
配列と連結リストは何が違うのか?
配列と連結リストは、データが順番に並んでいるという点において同じです。
しかしながら、「データにアクセスする方法」が異なります。
- 配列:データに直接アクセス
- 連結リスト:リストの先頭から順番に要素を辿ってアクセス

連結リストの場合、要素の数が多ければ多いほど目的のデータのアクセスには時間を要します。
となれば、「配列のほうが良くない?」と思うかも知れませんが、連結リストには連結リストのメリットがあります。
それは「データの挿入、削除をするとき」に現れます。
配列に要素を挿入、削除する場合は後ろの要素全てを1つずつずらさねばなりません。
そのため、要素数が多ければ多いほど処理に時間がかかります。
しかしながら、連結リストの場合はポインタを変更すればそれだけでデータの挿入、削除が可能なので処理が迅速です。
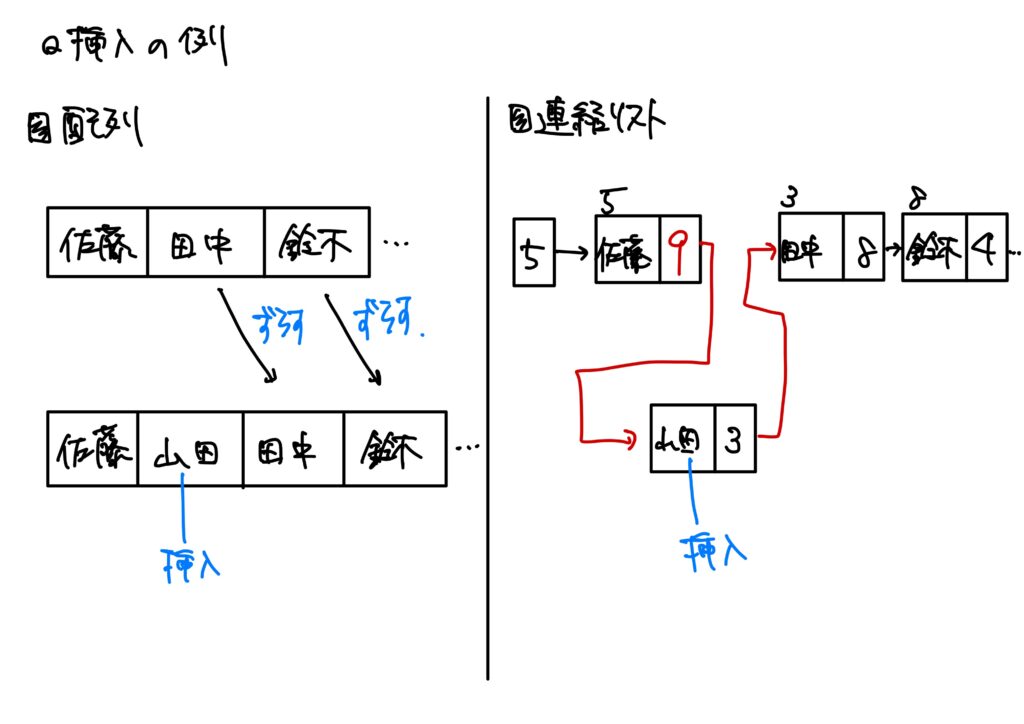
基本情報技術者試験では配列と連結リストの違いが出題されますので要注意です。
連結リストの分類
連結リストには
- 単方向リスト
先頭から末尾まで一方向にデータを繋げた連結リスト。
先頭から末尾の方向でしかデータをたどることが出来ない。 - 双方向リスト
双方向にデータを繋げた連結リスト。
先頭から末尾へ、末尾から先頭へデータをたどることができる。 - 線形リスト
先頭から末尾まで直線状に要素が繋がっている連結リスト。 - 環状リスト
末尾と先頭を繋げて環の形(環状)に要素が繋がっている連結リスト。
があります。

木構造
木構造
木構造とは、階層構造を持つデータ構造を指す。
木構造の各部分の名称
上図の○で表された箇所(枝分かれする箇所)を「節」と言います。
木構造では、節がデータを保持します。
節の中でも最上位の節を「根」と言い、また末端の節を「葉」といいます。
木構造の親子関係
木構造の節同士には関係があります。
分岐元を「親」、分岐先を「子」といいます。

親は数に制限なく子を持つことが出来ます。
木構造の中でも、親が0~2個の子を持つ木構造を二分木、親が0~3個の子を持つ木構造を三分木と呼びます。
一般化すれば、親が0~\(n\)個の子を持つ木構造を\(n\)分木と言います。
すなわち、分木というのは、節が最大でいくつの子に分かれるのかを表しています。
二分木探索
二分木の中でも親子の値が
左の子孫 < 親 < 右の子孫
となっているものを「二分探索木」といいます。
ただし、ここでいう子孫とは、「親よりも下にあるデータ」を指します。
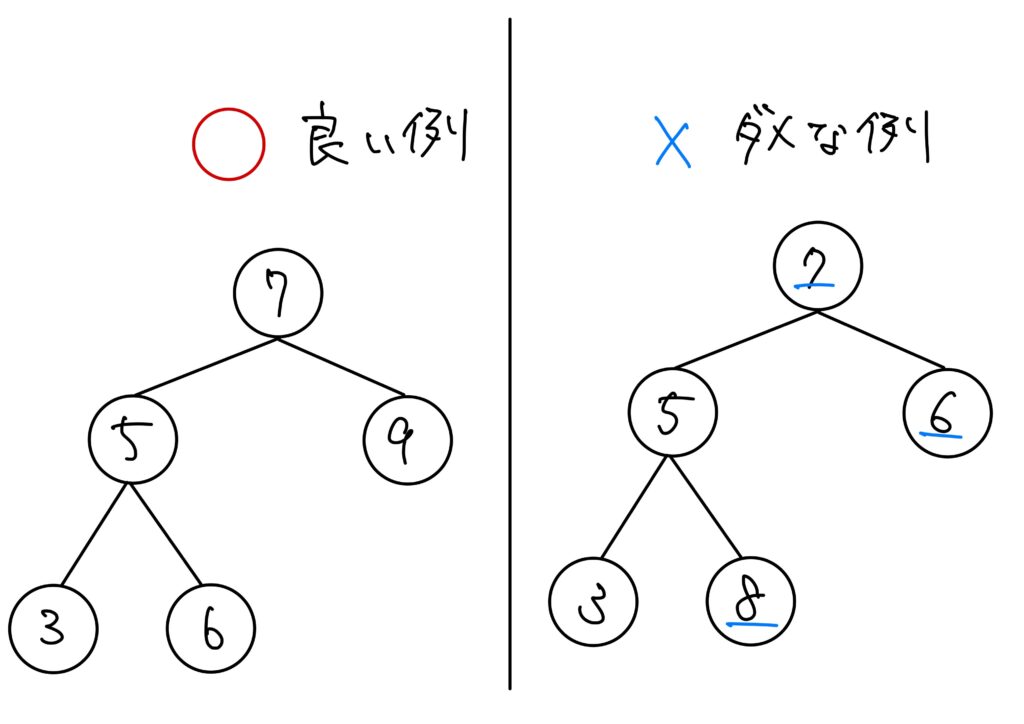
二分探索木のメリット
なぜ「左の子孫<親<右の子孫」の関係に並べるかというと、データを見つけるのに便利だからです。
二分探索木では、根から葉までの階層の数だけ値を調べれば、目的のデータを見つけ出すことが出来ます。
一方で、親子が無関係に繋がった木構造では、節を1つずつ調べる必要があります。
つまり、無関係な状態で勝手に木構造を作ってしまうと結局全探索しないといけなくなるので、某かの関係を入れる必要があり、その一例が先の関係ということなのです。
アルゴリズムの基本
アルゴリズム
アルゴリズムとは、問題を解決するときの手順を指す。一般社会ではあまり聞き慣れないかも知れませんが、コンピュータの世界ではとても重要な用語です。
基本情報技術者試験では「流れ図」が頻出です。
アルゴリズムの表現方法
アルゴリズムは以下の4つの方法で表現されます。
- 文章:文字による表現
- 流れ図:図による表現
- 数式:関数による表現
- プログラム言語:コンピュータが理解できる言語による表現
今回は、「与えられた数値に対して、絶対値を返すアルゴリズム」を例に述べます。
文章
「与えられた数値に対し、絶対値を返すアルゴリズム」を文章で書けば、以下です。
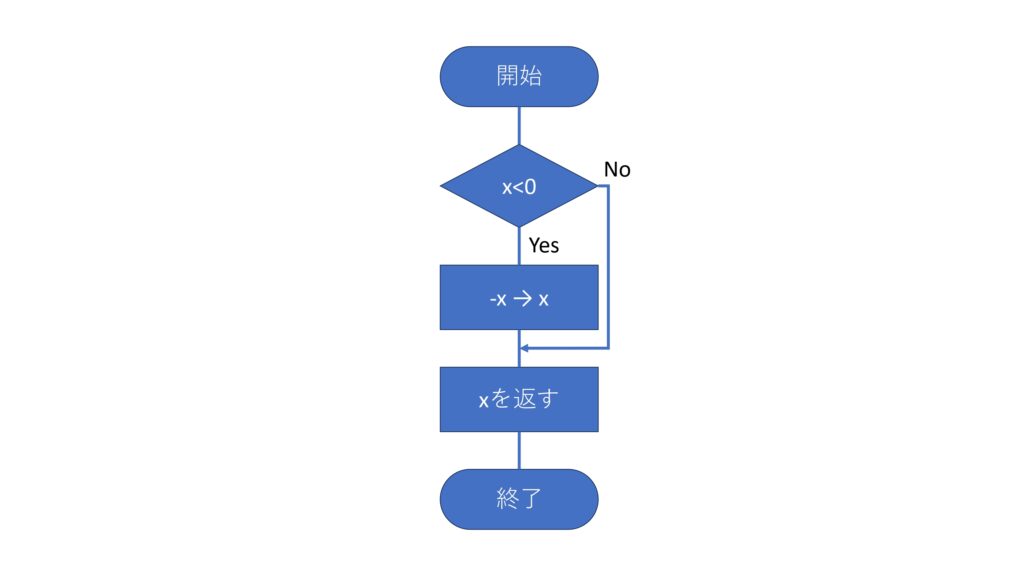
① \(x<0\)ならば②へ、\(x\geq0\)ならば③へ。
② \(-x\rightarrow x\)
③ \(x\)を返す。
②の手順の中にある「\(\rightarrow\)」は代入を表します。
例えば、\(x=3\)ならば、\(x\)に\(-3\)を代入せよ、と言うことになります。
文章によるアルゴリズムの表現のメリットとしては、数学記号と文字さえ読めれば、その他の知識がなくてもアルゴリズムを理解できることです。
流れ図
流れ図(フローチャート)とは、アルゴリズムを視覚的にわかりやすく表現した図を指す。
「与えられた数値に対して、絶対値を返すアルゴリズム」を流れ図で表せば、次です。
流れ図で使用する記号
流れ図で使用する記号はJIS(日本産業規格)によって規格化されています。
基本情報技術者試験でよく出題されるのは、以下の5種類です。
記号を問題として問われることはありませんが、形状と役割は覚える必要があります。
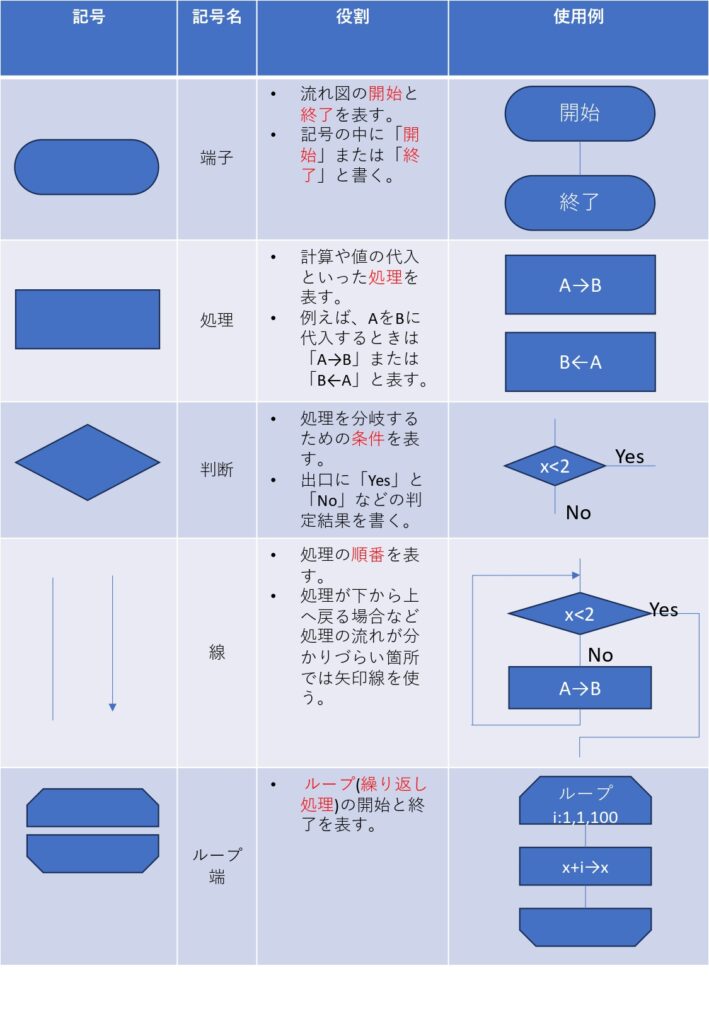
ループ端の表記法は暗記不要
ループ端の中には繰り返し処理の条件が記入されています。
しかし、条件の記入方法は問題文中に必ず注記されますので、暗記不要です。
例えば、先程の図の例では、「変数名:初期値、増分、終値」という意味です。
すなわち、
- 変数\(i\)は「1」からはじまり(初期値)、
- ループ処理を繰り返すたびに「値は1ずつ増加」(増分)し、
- 「\(i\)が100になったとき」(終値)にループ処理が終わる
という意味です。
数式
「与えられた数値の絶対値を返すアルゴリズム」を数式で表せば、
$$
f(x)=
\begin{cases}
-x&(x<0)\\
x&(x\geq0)\end{cases}
$$
です(そりゃそうだ)。
関数
アルゴリズムにおける関数というのは、複数の処理をひとまとめにしたものです。
例えば、以下のような関数があります。
- 数値の絶対値を求める関数
- 数値を3倍する関数
- 現在の日付を表示する関数
などなどです。
「絶対値を求める関数」を利用すれば、いつでも任意の数値の絶対値を求めることが出来ますし、同様にして「数値を3倍する関数」を用いればその関数を呼び出すことでいつでも任意の数値を3倍することが出来ます。
関数を用いる上で、2つの用語を覚える必要があります。
- 引数:関数に渡す値。\(y=f(x)\)における\(x\)。
- 戻り値:関数が返す結果。\(y=f(x)\)における\(y\)。

プログラム言語
「与えられた数値の絶対値を返すアルゴリズム」をプログラム言語で表すと、以下です。
f(x):
if x<0 then
return -x
else
return xこの関数\(f(x)\)を流れ図で表すと、以下です。

また、この関数の書式は以下です。
f(x):
if 条件 then
条件が真なるときの処理
else
条件が偽なるときの処理尚、基本情報技術者試験においてアルゴリズムをプログラム言語で表すときは、以下のように1行で表されることが多いです。
f(x) : if x<0 then return -x else return x基本情報技術者試験では特定のプログラム言語(C言語やらJava言語やら)の書式は問われません。
故に、「if」「then」「else」「return」の4つの意味を理解しておくだけで読み解けます。
| キーワード | 意味 |
| if | 後ろに「条件」を書く。 |
| then | 後ろに「条件が正しいときの処理」を書く。 |
| else | 後ろに「条件が正しくないときの処理」を書く。 |
| return | 後ろに「戻り値」を書く。 |
アルゴリズムの分類
基本情報技術者試験では、以下のアルゴリズムが出題されます。
- 整列アルゴリズム:データを並べるためのアルゴリズム
- 探索アルゴリズム:データを見つけ出すためのアルゴリズム
- 再帰的アルゴリズム:処理の途中で自分自身を呼び出すアルゴリズム
整列アルゴリズム
整列アルゴリズム
整列アルゴリズムとは、データを特定の順番に並べるアルゴリズムを指す。ソートアルゴリズムと呼ばれることもあります。
| 種類 | 解説 |
| バブルソート | 配列の先頭から順に、隣り合ったデータを比較して、順序が違っていたら交換することを繰り返すアルゴリズム |
| 選択ソート | 配列の先頭から順次、データを比較して最小値を選択肢、選択した最小値を先頭のデータと交換することを繰り返すアルゴリズム |
| 挿入ソート | 整列済みの要素を持つ配列に対して、未整列のデータを適切な場所に挿入するアルゴリズム |
| クイックソート | 「基準値よりも小さいグループ」と「基準値よりも大きいグループ」の2つに分け、分けたグループに対しても同じ手順を繰り返すアルゴリズム |
基本情報技術者試験では、クイックソートが頻出で、それ以外が出題されることは稀だそうです。
クイックソート
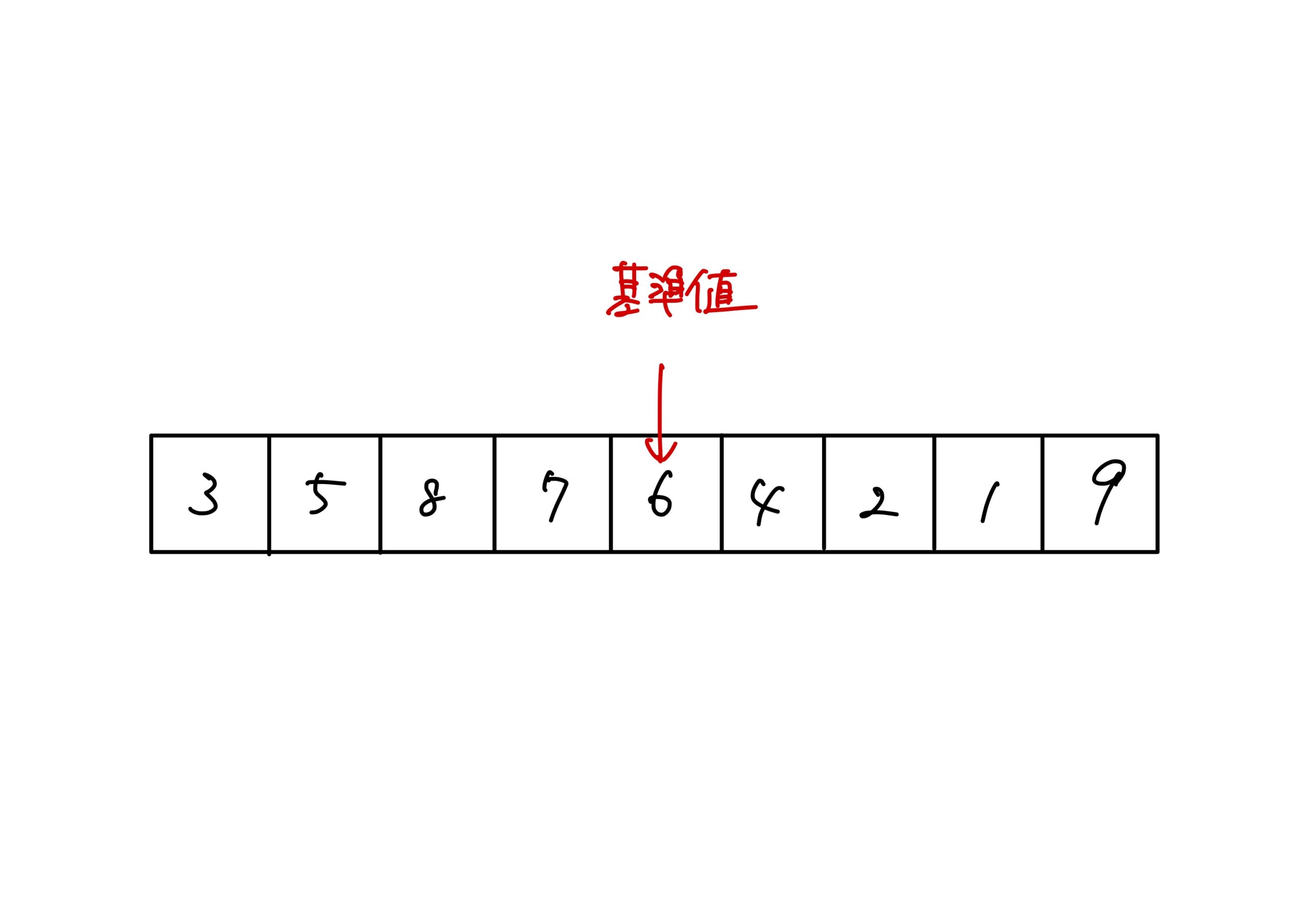
具体例として、バラバラに配置された1から9までの数を昇順に並べる手順を紹介します。
- 基準値を決める。 基準値はどこでも良いのですが、ここでは列の真ん中の数字「6」とします。
- 基準値「6」よりも小さい数を左のグループに配置し、「6」よりも大きい数を右のグループに配置する。
- 左右に分けられたグループごとに再度、基準値を決めて、2つのグループに分ける。
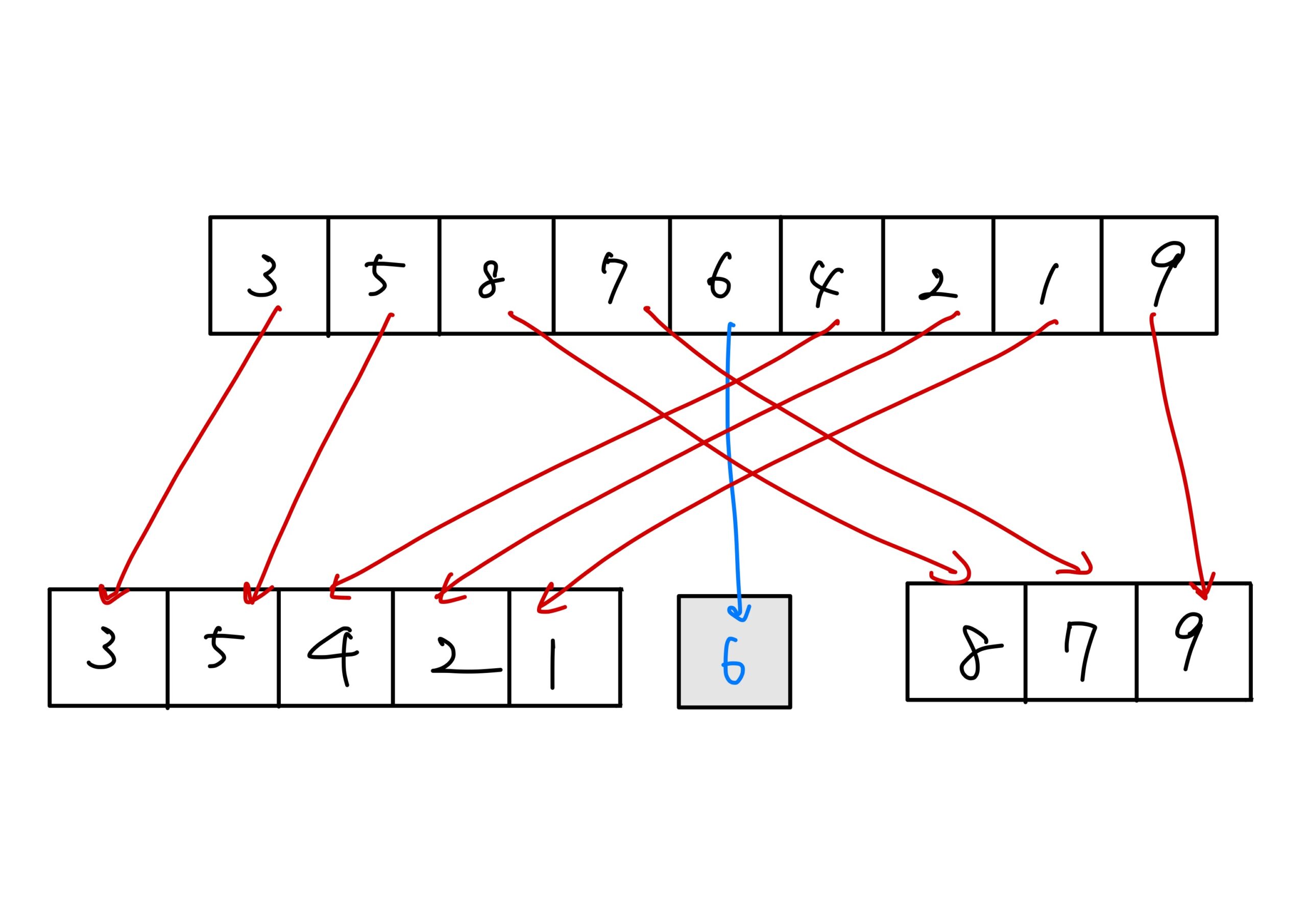
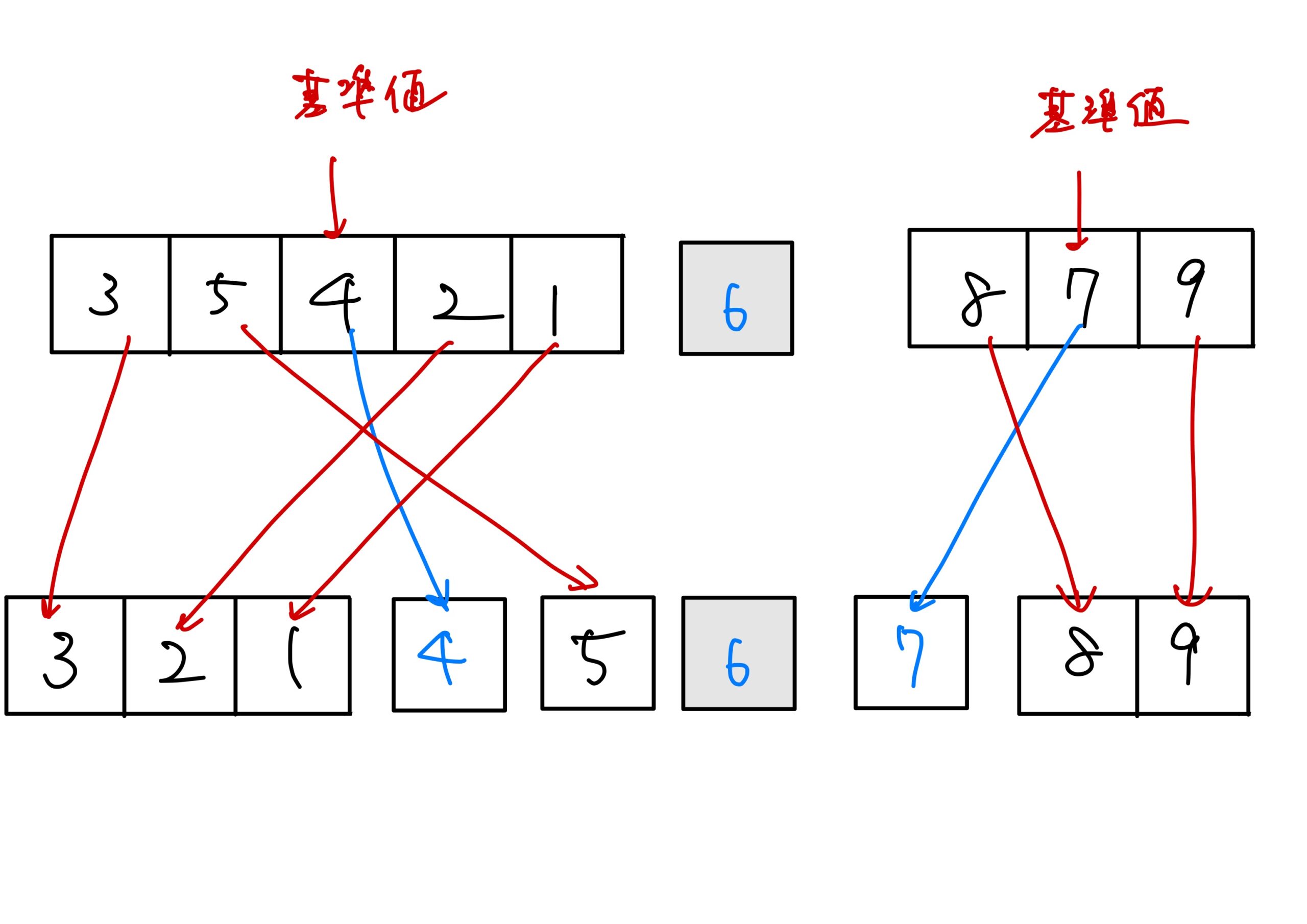
この手順を繰り返して「これ以上分割できない」というところまで手ヌンを進めると数字が昇順に整列します。
探索アルゴリズム
探索アルゴリズム
探索アルゴリズムとは、特定のデータを見つけ出すアルゴリズムを指す。主とする探索アルゴリズムは以下の3つです。
| 種類 | 説明 |
| 線形探索法 | 先頭のデータから順番に1つずつ照合することで目的のデータを見つける。 |
| ハッシュ法 | ハッシュ表をつかて目的のデータを見つける探索アルゴリズム。 |
| 二分探索法 | 調べる範囲を半分に切り分けながら目的のデータを見つける探索アルゴリズム。 |
ハッシュ法と二分探索法が頻出です。
ハッシュ法
ハッシュ法
ハッシュ法とは、探索対象のデータをハッシュ値に変換し、ハッシュ値を使って目的のデータを見つける探索アルゴリズムである。ハッシュ法は「ハッシュ表探索法」とも呼ばれます。
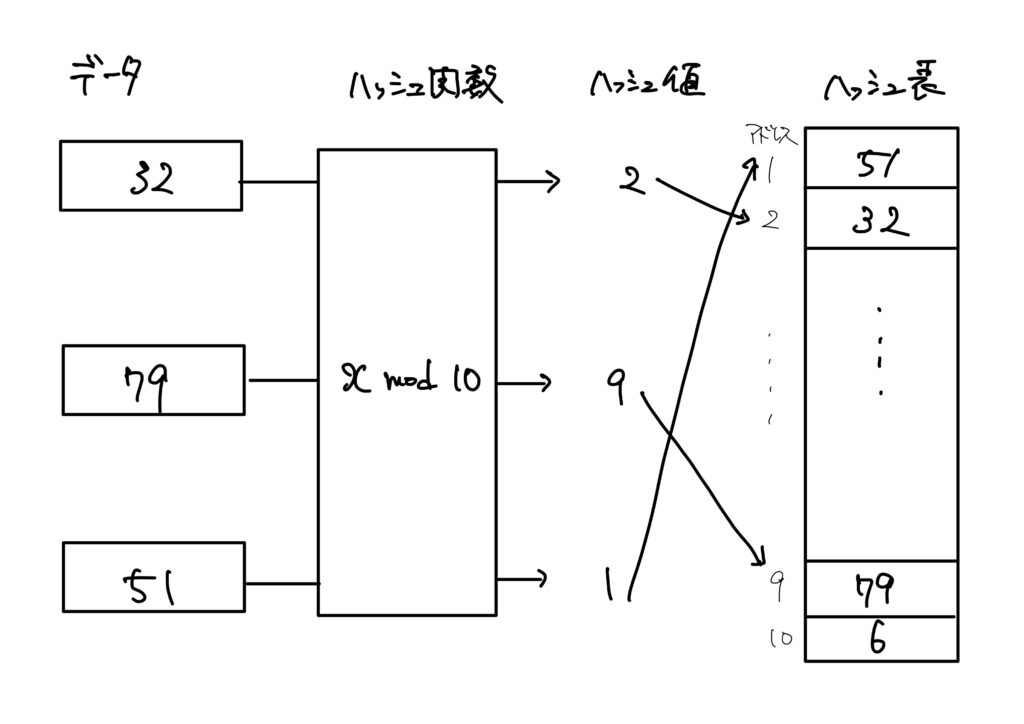
具体例として、ハッシュ法で上図から「32」を探索する手順を述べます。
ハッシュ法ではまず、ハッシュ関数を使って、探索対象となるデータをハッシュ値に変換します。
ハッシュ値とは、ハッシュ関数の出力です。
代表的はハッシュ関数の1つが剰余です。
ハッシュ関数が「入力した値を10で割った余りを出力する」関数ならば、このハッシュ関数に32を入力すると2が出力されます(\(32\equiv 2\ ({\rm mod}\ 10)\))。
故にこの場合のハッシュ値は2です。
目的のデータはハッシュ値を添え字とした、配列の要素に格納されます。
このようにハッシュ値を添え字に持つ配列をハッシュ表といいます。
つまり、この場合は添字が2である格納場所を探索すれば32を1回で見つけることが出来ます。
ハッシュ法の弱点
入力値が異なっていてもハッシュ値が同じ値になってしまうケースが存在することです。
剰余だとまさにそのとおりですね。
これを衝突と言います。
基本情報技術者試験では「ハッシュ法のデメリットは衝突が起こる可能性があること」というポイントが出題されます。
二分探索法
二分探索法
二分探索法とは、調べる範囲を半分に分割することで目的のデータを見つけるアルゴリズムを指す。二分探索法には以下の2つの特徴があります。
- データを予め整列させておく必要がある
- データを2つに分けながら探索する
例を述べます。
1から9の数字が昇順に並んでいます。
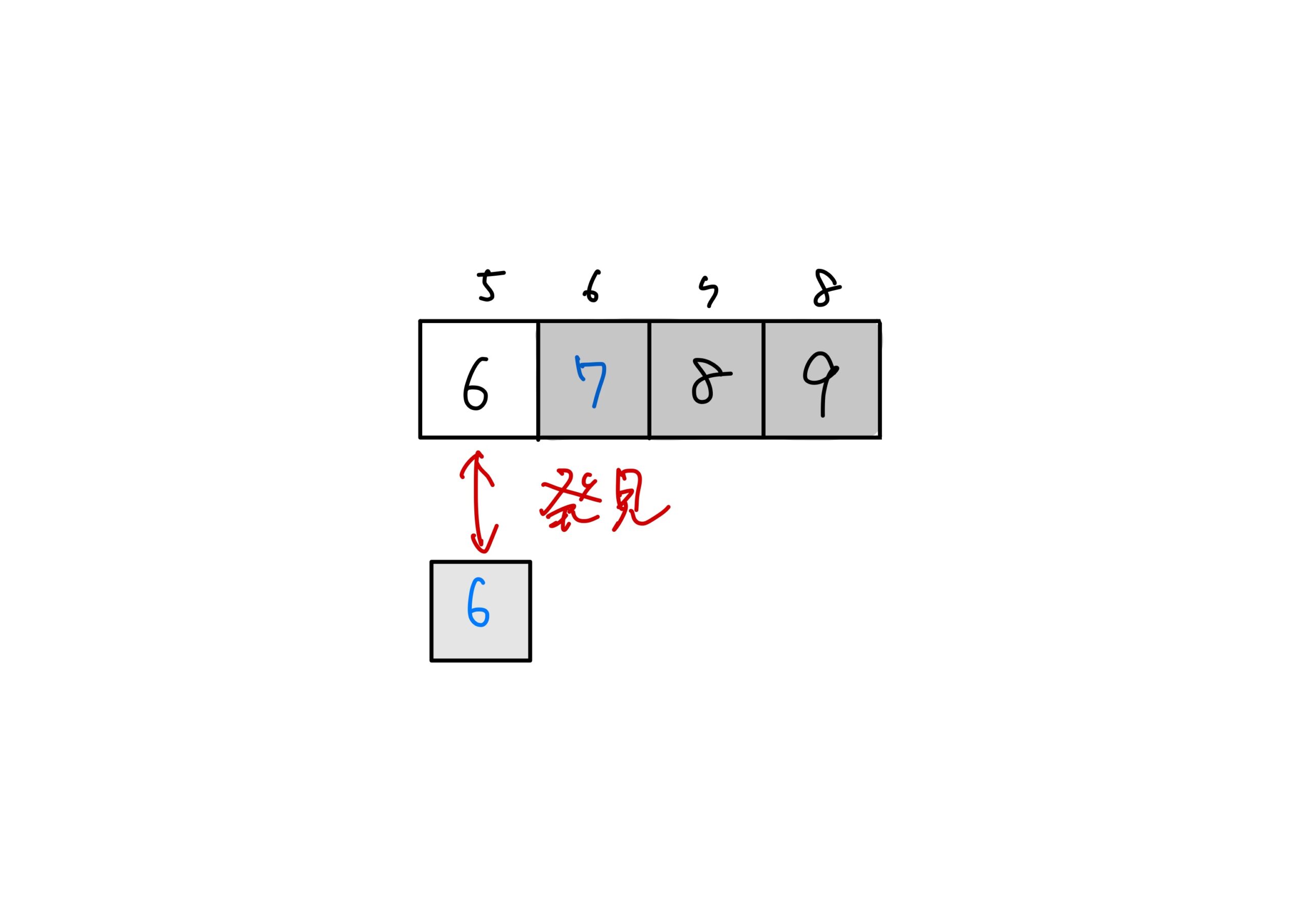
この配列から「6」を二分探索で見つける方法を述べます。
- 列の中から中央の要素を見つける 中央の要素は先頭の添字と末尾の添字の合計を2で割れば見つけられます。
- 右半分の要素に対して、1.と同じ操作をする \((5+8)\div 2=6.5\fallingdtoseq6\)です。
今回は、\((0+8)\div2=4\)です。
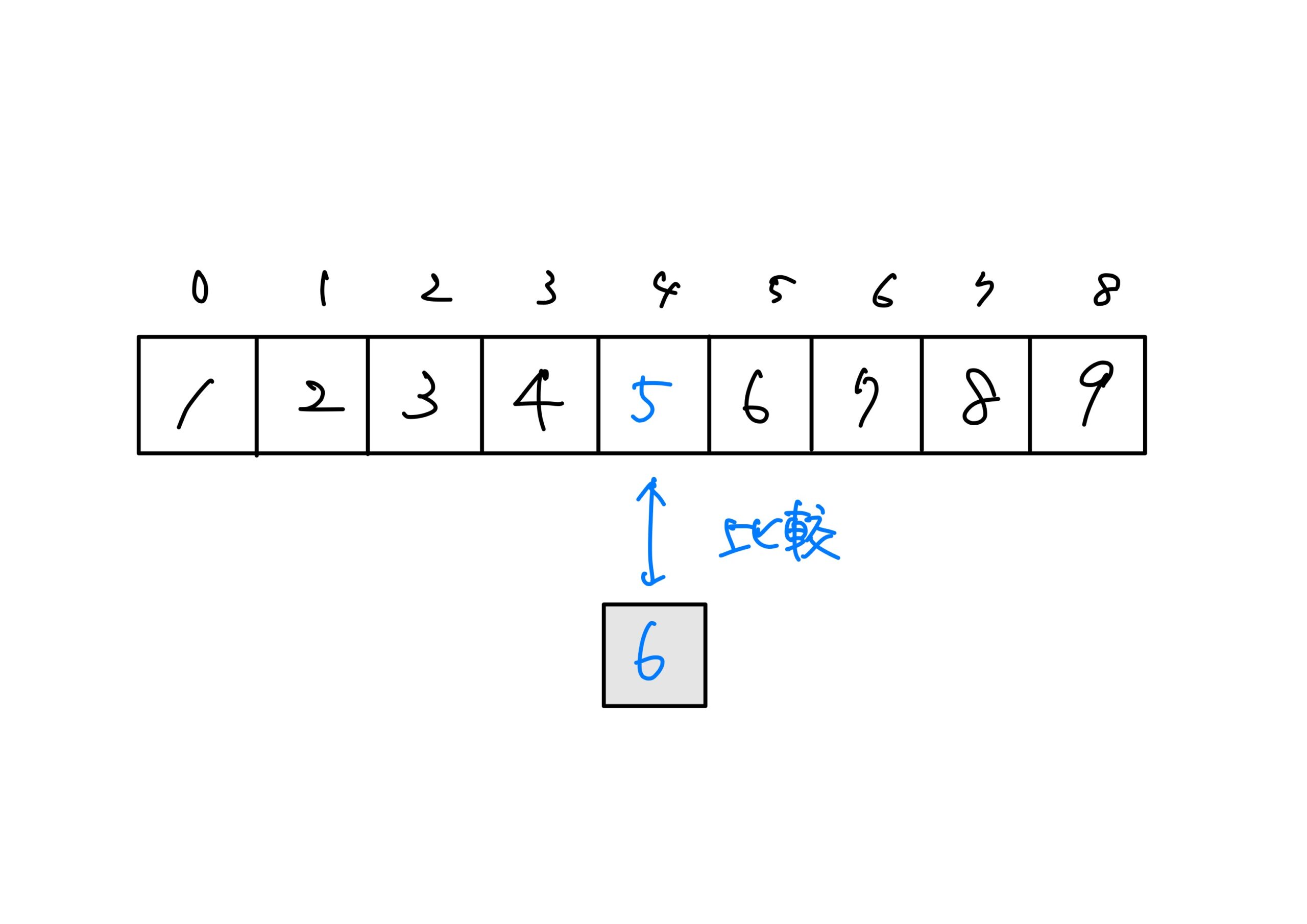 \(8>5\)により、列の左半分のグループに6 が存在しないことがわかります。
\(8>5\)により、列の左半分のグループに6 が存在しないことがわかります。
小数点以下を切り上げるか切り捨てるかは、どちらでもOKです。
添字6の要素7と探索対象の6を比較します。
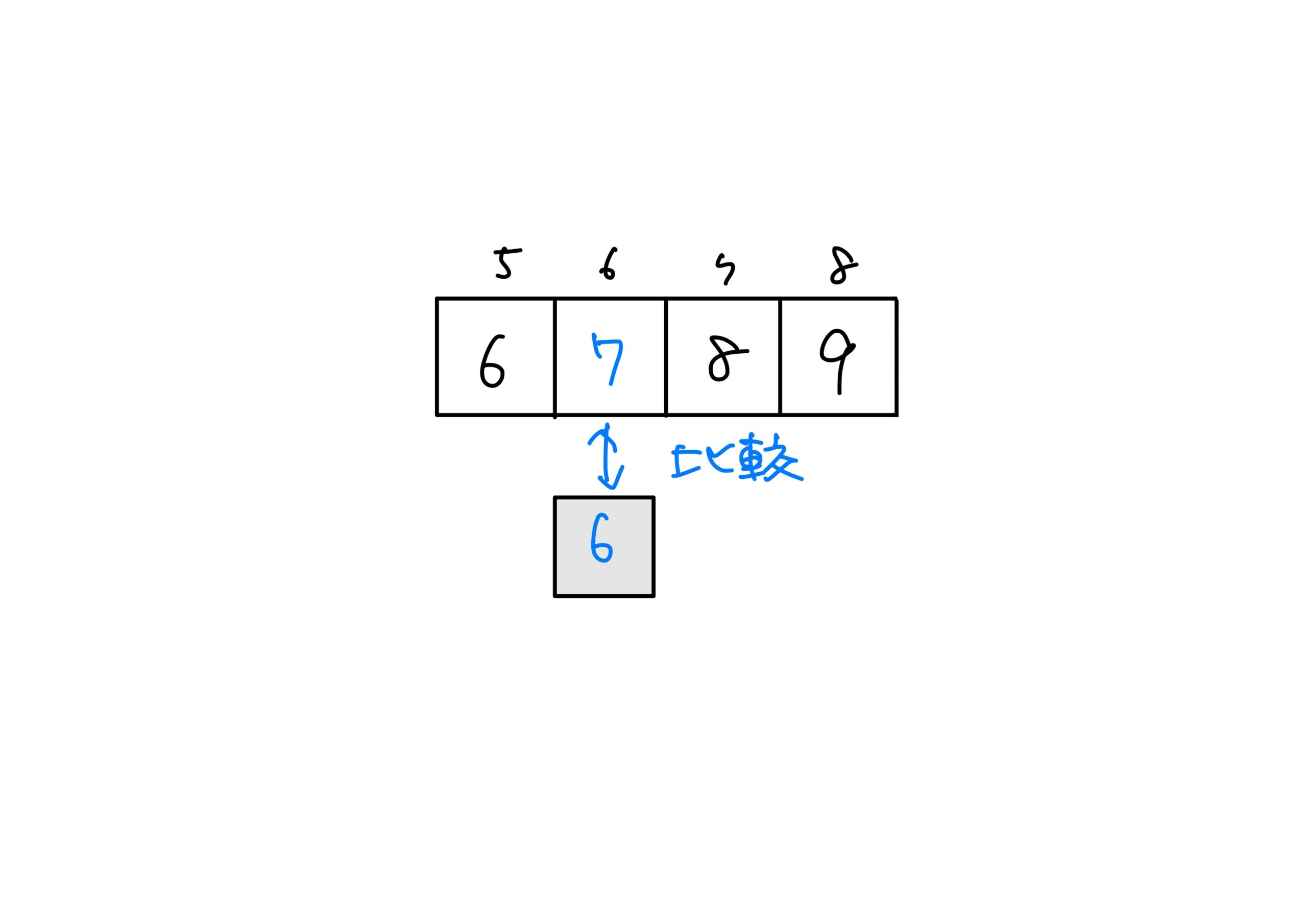 \(6<7\)により、探索範囲を左半分のグループに絞ります。
この操作を続けることで目的のデータを見つけることが出来ます。
\(6<7\)により、探索範囲を左半分のグループに絞ります。
この操作を続けることで目的のデータを見つけることが出来ます。
再帰的アルゴリズム
再帰的アルゴリズム
再帰的アルゴリズムとは、処理の中で自分自身を呼び出すアルゴリズムを指す。再帰とは繰り返しを意味します。
基本情報技術者試験において再帰的アルゴリズムは主として「総和、剰余、階乗」の3つを求める際に出題されます。
再帰的アルゴリズムによる総和の求め方
基本情報技術者試験では頻出のようです。
「1から5までの整数の総和」を例に述べます。
この問題の答えは15です。
数式での表現で
この問題を数式で表現すれば、以下です。
$$
f(x)=
\begin{cases}
1&(x\leq 1)\\
x+f(x-1)&(x>1)
\end{cases}
$$
まさに、自身を呼び出して使っています。
この、処理の中で自分自信を呼び出している箇所が再帰的アルゴリズムです。
\begin{eqnarray}
f(5)&=&5+f(4)\\
&=&5+4+f(3)\\
&=&5+4+3+f(2)\\
&=&5+$+3+2+f(1)\\
&=&5+4+3+2+1
\end{eqnarray}
プログラム言語で表現
プログラム言語で表現すれば以下です。
f(x): if x≦1 then return 1 else return x+f(x-1)アルゴリズムの計算量を算出する問題
異なるアルゴリズムであっても、出力が同じ場合があります。
このとき、実行時間が短く、メモリの使用量が少ないアルゴリズムの方が優秀です。
オーダー(計算量)とは
アルゴリズムを完了するために必要な計算量のことをオーダーといいます。
データ\(\)と計算量の関係を表す記法をオーダー記法といい、O(計算量)で表します。
尚、オーダーは「これ以上大きくならない」という最大の計算量を表します。
アルゴリズムのオーダー
一覧を表示します。
| アルゴリズム | オーダー記法による計算量 |
| ハッシュ法 | \(O(1)\) |
| 二分探索法 | \(O(\log_2n)\)または\(\log n\) |
| 線形探索法 | \(O(n)\) |
| クイックソート | \(O(n\log n)\) |
プログラムの性質と種類
プログラムという言葉は昨今聞き馴染みがあるかもしれませんが、一体何者でしょうか。
一言で述べれば
コンピュータに対する命令書
です。
コンピュータは、我々が書いたプログラム(命令書)に従い、処理を実行します。
基本情報技術者試験では、プログラムに関する内容として「再帰(リカーシブ)」と「再入可能(リエントラント)」の2つの性質と、プログラム言語の種類である「JacaBeans」「Javaアプレット」「 Javaサーブレット」が頻出のようです。
プログラムの性質
先述の再帰も性質の一つです。
ここでは基本情報技術者試験に頻出の代表的性質を4つ紹介します。
- 再帰(リカーシブ)
- 再入可能(リエントラント)
- 再配置可能(リロケータブル)
- 再使用可能(リユーザブル)
先程、「再帰と再入可能が頻出」と述べましたが、実のところ基本情報技術者試験で問われるのは「再帰と再入可能の2つだけ」のようです。
ゆえに、本記事ではその2つだけを紹介します。
再帰(リカーシブ)
これはすでに述べているので、復習程度に留めます。
再帰とは、プログラム実行中に自分自信を呼び出す事ができる性質を指します。
再帰は「繰り返し」という意味です。
この性質を持つプログラムを「再帰プログラム」といいます。
再入可能(リエントラント)
再入可能
再入可能(リエントラント)とは、複数のプログラムから同時に呼び出されても正しく動作する性質である。例えば、プログラムAとプログラムBが同時にプログラムCを呼び出したときに、プログラムCが正しく動作すれば、プログラムCは再入可能プログラムであると言います。

「例は?」と思うかも知れませんが、これだけ知ってれば良いようです。
名称に「Java」が含まれる用語
最も有名なプログラムの言語の一つに「Java」があります。
実は、名前にJavaが着く用語がいくつかあり、混同しやすいため試験にも頻出です。
特徴を把握することをおすすめします。
| 用語 | 説明 |
| Java | コンピュータの機種やOSに依存せずソフトウェアを開発できるプログラム言語 |
| Javaアプリケーション | Javaで書かれたアプリケーションソフトウェア |
| Javaアプレット | サーバーからダウンロードして、クライアント側のWebブラウザ(※後の記事で)上で実行されるJavaで書かれたプログラム。 クライアント側へ転送されて実行されるプログラムを「アプレット」という。 |
| Javaサーブレット | サーバー上で実行される、動的Webページ(後の記事で)を作るためのJavaで書かれたプログラム。 動的処理(ユーザーの要求に合わせてその都度ことなる Webページを表示する処理。ex.Amazonのオススメ欄など)を実現する際に利用する。 |
| JavaBeans | Javaのプログラムにおいて、よく使われる機能を部品化、再利用できるようにコンポーネント化するための仕様。 |
| JavaScript | 動的なWebページを作るためのプログラム言語。 「Java」と名前は似ているが、全く別物のプログラム言語。 |
その他の言語
本章では、先に解説したJava以外の言語について述べます。
基本情報技術者試験では、「XML、CSS、Ajax」の3つの用語が頻出です。
そして、出題傾向が明確故、コスパが良い分野です。
HTML
いきなりXMLでもCSSでもAjaxでもない言語を持ち出しましたが、上記3つを知る上でHTMLを知る知らないでは大きく異なると思いますので、ざっくりではありますが、HTMLから述べます。
HTML
HTML(HyperText Markup Language)とは、Webページを作成する際に利用されているマークアップ言語を指す。ここで、マークアップ言語とは「Webサイト文章といったテキストに目印付けを行い、コンピューターに認識させるための言語」です。
本ブログも部分的にHTMLを使って書いています。
HTMLでは、タグと呼ばれる要素を用いてWebページの論理構造や文字要素を指定します。
論理構造というのは、そのWebページに「どのような要素があり、またそれがどのような関係性を持っているか」を示すものです。
イメージが湧きにくいと思いますので、例を挙げます。
<html>
<title>たいとる</title>
<body>本文</body>
</html>上記において< >で囲まれた文字をタグと言います。
上記のHTMLをテキストエディタなどで書き、「test.html」など拡張子をhtmlにして保存し、それをブラウザで表示してみるとわかりやすいかも知れません。
もっと簡単にイメージが湧くのは、chromeで
- mac:⌘-Option-U
- windows:Ctrl + U
を押下していただければ、htmlのソースコードが見れます。
XML
XML
XML(eXtensible Markup Language)とは、HTMLとは異なり、個々人自身が定めたタグを使ってデータを記述するマークアップ言語を指す。Extensibleというのは拡張可能という意味です。
つまり、XMLの場合は「タグを自分で定めることができる(拡張できる)」ということを表しています。
HTMLの用途がWebページの作成であるのに対し、XMLの用途は「Web上でデータを交換すること」です。
<生徒>
<生徒番号>123</生徒番号>
<名前>オノコウスケ</名前>
<電話番号>090-XXXX-YYYY</電話番号>
</生徒>こんな感じです。
最も、私は生徒ではないのですけどね。
XMLの場合も、HTMLと同様にして、タグを使ってデータを記述します。
こうすることで、Web上でデータをやり年できるようになります。
また、XMLのメリットは、人間とコンピュータの双方が読みやすい形式であることです。
| 言語 | 記述対象 | 記述方法 | 用途 | 独自タグ |
| HTML | 論理構造 | タグ | Webページ作成 | 不可 |
| XML | 論理構造 | タグ | データ交換 | 可 |
CSS
CSS
CSS(Cascading Style Sheets)とは、HTMLの文章の文字の大きさ、文字の、行間などのデザイン(視覚的表現)を指定する言語である。とどのつまり、CSSというのはHTMLでWebページを作成する際、デザインを司る言語ということです。
本ブログでも部分的にCSSを使っています。
Webページは通常、HTMLとCSSの2つを使って制作します。
実は、CSSはデザイン部分をHTMLファイルから切り取ったようなものなので、使わなければならないということではありません。
ただ、HTMLとCSSを使い分けることで、「論理構造」と「視覚的表現の情報」を切り分けることができるのです。
例えば、以下です。
color:#333333; →色の指定
font-size:12pt; →文字の大きさの指定Ajax (あじゃっくす)
Ajax
Ajax(Asynchronous JavaScript and XML)とは、Webおえー事情で画面を切り換えることなく、動的なユーザーインターフェースを実現する技術である。画面遷移
Ajaxの技術を利用していない従来のWebページでは、以下の2つの処理を行ってブラウザに表示する情報を更新していました。
- サーバーと通信して、次のWebページを取得する
- 取得したWebページをブラウザ上に表示する
上記のように、ブラウザに表示するWebページを切り換えることを画面遷移と言います。
Googleのトップから、なにか単語を入力して検索したときに出る検索結果の画面へ切り替わるというのも画面遷移です。
同期通信と非同期通信
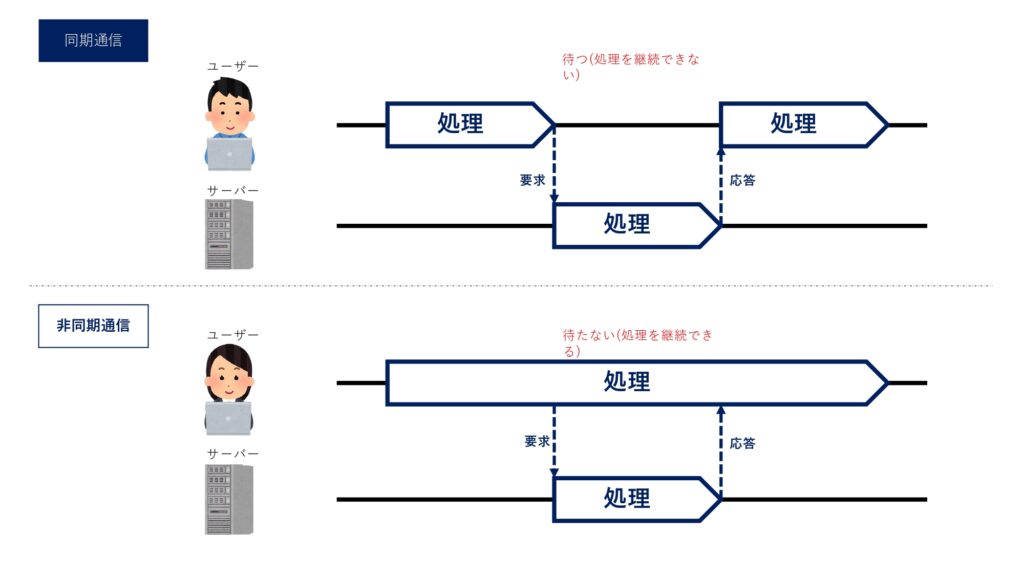
画面遷移でWebページが切り替わる方法では、ユーザーは画面遷移が完了するまで(サーバー次のWebページを取得し、ブラウザ上に表示するまで)、新しいWebページを閲覧することが出来ません。
このように「サーバーの処理が完了するまで次の処理に進まない方式」を同期通信といいます。
同期通信ではユーザーがWebページのボタンを押すたびにWebページが切り替わるのを待つ必要があるため、使い勝手がよくありません。
そこで登場したのがAjaxです。
AjaxはJavaScriptとXMLを使うことでユーザからは見えないところでサーバーとつうしんを実現する技術です。
この技術によってサーバーの処理が完了するのを待つことなく、新しい異データを受信できます。
ゆえに、Webページが切り替わるのを待つ必要もなくなります。
このように「サーバーの処理が終わるのを待たずに次の処理に進む方式」のことを「非同期通信」といいます。
ちなみに、Ajaxの先頭のAはAsynchronous(非同期)の頭文字です。
同期通信、非同期通信
- 同期通信 サーバーの処理が完了するまで次の処理に進まない方式
- 非同期通信 サーバーの処理が終わるのを待たずに次の処理に進む方式
Ajaxを利用したWebアプリケーションの代表例がGoogleMapです。
GoogleMapでは、ブラウザに表示された地図をドラッグすると、同じWebページ上に新しい地図が表示されます。
このとき、Webページの切り替えは行われません。
復習問題
実際に出題された問題を一緒に解いてみましょう!
データ構造の一つであるリストは、配列を用いて実現する場合と、ポインタを用いて実現する場合とがある。配列を用いて実現する場合の特徴はどれか。ここで、配列を用いたリストは、配列に要素を連続して格納することによって構成し、ポインタを用いたリストは、要素から次の要素へポインタで連結することによって構成するものとする。
- 位置を指定して、任意のデータに直接アクセスすることができる。
- 並んでいるデータの先頭に任意のデータを効率的に挿入することができる。
- 任意のデータの参照は効率的ではないが、削除は挿入の操作を効率的に行える。
- 任意のデータを別の位置に0移動する場合、隣接するデータを移動せずにできる。
答え
1配列を用いたリストでは、添字を使うことでデータを直接参照できます。
一方で、ポインタを用いたリスト(連結リスト)では、リストn先頭から順番に要素をたどっていく必要があり、そのために要素数が多ければ多いほど参照に時間がかかります。
その他の選択肢は全て連結リストの特徴です。
関数\(f(x,y)\)が次の通り定義されているとき、\(f(775,527)\)の値は幾らか。ここで、x mod yはxをyで割った余りを返す。
f(x,y): if y=0 then return x else return f(x, x mod y)
- 0
- 31
- 248
- 527
答え
2単純に計算すればOKです。
プログラムの意味としては、
- y=0が正しい場合はxを返す。
- y=0が正しくない場合は、f(y, x mod y)を返す。
です。
\begin{eqnarray}
f(775,527)&=&f(527,775\ {\rm mod }\ 527)\\
&=&f(527,248)\\
&=&f(248,527\ {\rm mod }\ 248)\\
&=&f(248,31)\\
&=&f(31,248\ {\rm mod }\ 31)\\
&=&f(31,0)\\
&=&31
\end{eqnarray}
探索方法とその実行時間のオーダーの適切な組み合わせはどれか、ここで、探索するデータの数をnとし、ハッシュ値が衝突する(同じ値になる)確率は無視できるほど小さいものとする。また、実行時間のオーダーが\(n^2\)であるとは、n個のデータを処理する時間が\(cn^2\)(cは定数)で抑えられることをいう。
| 二分探索 | 線形探索 | ハッシュ探索 | |
| ア | \(\log_2n\) | \(n\) | 1 |
| イ | \(n\log_2n\) | \(n\) | \(\log_2n\) |
| ウ | \(n\log_2n\) | \(n^2\) | 1 |
| エ | \(n^2\) | 1 | \(n\) |
答え
アXMLの特徴として、最も適切なものはどれか。
- XMLでは、HTMLに、Webページの表示性能の工場を重な目的として機能を追加している。
- XMLでは、ネットワークを介した情報システム間のデータ交換を容易にするために、任意のタグを定義することができる。
- XMLで用いることができるすたいる言語は、HTMLと同じものである。
- XMLは、SGMLを基に開発されたHTMLとは異なり、独自の仕様として開発された。
答え
2結
今回は、基本情報技術者試験におけるデータ構造、アルゴリズム、プログラムについて、情報及びコンピュータの素人目線から説明しました。
問題が解けるということに重きを置き説明しました。
データの構造には
- スタック:最後に格納したデータを最初に取り出す方式
- キュー:最初に格納したデータを最初に取り出す方式
- 配列
- 連結リスト
- 木構造
があるのでした。
アルゴリズムというのは問題を解決するときの手順を指すのでした。
プログラム、特にHTML、CSS、XML、Ajaxを述べました。
質問、コメントなどお待ちしております!
どんな些細なことでも構いませんし、この記事に限らず、「定理〇〇の△△が分からない!」などいただければお答えします!
Twitterでもリプ、DM問わず質問、コメントを大募集しております!


コメントをする